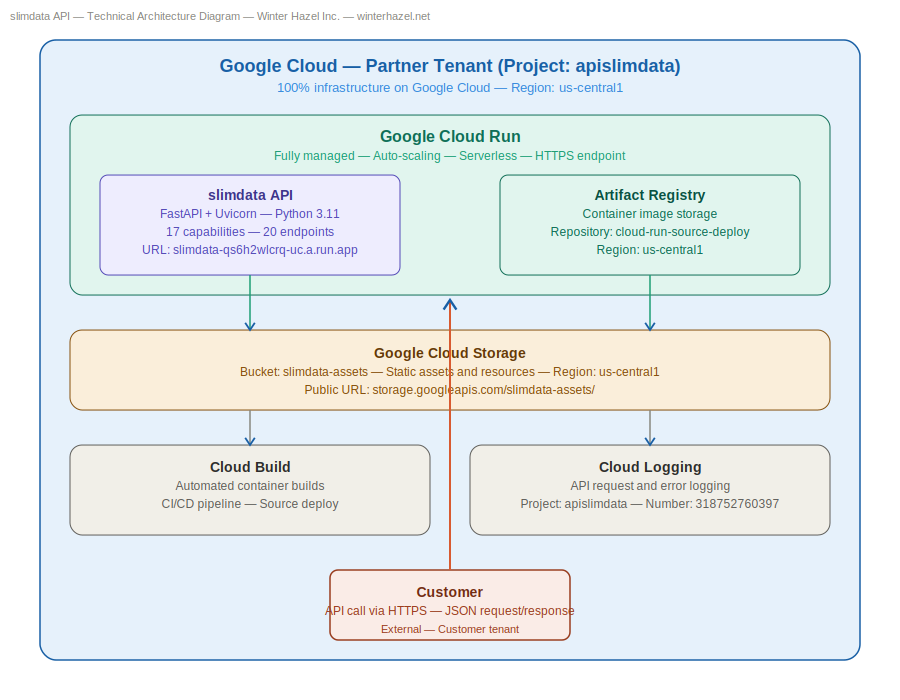
Python डेटा ऑप्टिमाइज़ेर API, जो Winter Hazel Inc. द्वारा विकसित किया गया है, आपके Python कोड और डेटाबेस में असमान्य डेटा प्रकारों की पहचान करता है और उन्हें सबसे कॉम्पैक्ट और कुशल प्रकारों से बदलता है जो आपके डेटा को सटीक रूप से बनाए रखते हैं
इनपुट: JSON प्रारूप में कैप्सुलेट किए गए Python डेटा संरचनाओं, कोड स्निप्पेट या डेटाबेस कनेक्शन स्ट्रिंग्स को API कॉल के माध्यम से भेजें
आउटपुट: अनुकूलित डेटा के साथ एक विस्तृत बचत रिपोर्ट प्राप्त करें जो मूल आकार, अनुकूलित आकार और कुल बचाए गए बाइट्स को दर्शाती है
यह सुविधा सीधे आपके डेटाबेस से जुड़ती है और टेबल और कॉलम को ओवरसाइज डेटा प्रकारों के लिए स्कैन करती है, प्रति पंक्ति बचाए गए बाइट्स के साथ सटीक सिफारिशें लौटाती है:
{"status":"success","result":{"optimized":[1000,2000,3000,4000,5000],"savings":{"original_type":"list","optimized_type":"array.h","original_size":40,"optimized_size":10,"saved":"30 bytes"},"type_detected":"list"}}
curl --location --request POST 'https://zylalabs.com/api/12866/python+data+optimizer+api/25666/optimize+data' --header 'Authorization: Bearer YOUR_API_KEY'
--data-raw '{"data": [1000, 2000, 3000, 4000, 5000]}'
{"status":"success","results":[{"optimized":[1000,2000,3000],"savings":{"original_type":"list","optimized_type":"array.h","original_size":24,"optimized_size":6,"saved":"18 bytes"},"type_detected":"list"},{"optimized":[1.5,2.5,3.5],"savings":{"original_type":"list","optimized_type":"array.f","original_size":24,"optimized_size":12,"saved":"12 bytes"},"type_detected":"list"}]}
curl --location --request POST 'https://zylalabs.com/api/12866/python+data+optimizer+api/25670/optimize+batch' --header 'Authorization: Bearer YOUR_API_KEY'
--data-raw '{"data_list": [[1000, 2000, 3000], [1.5, 2.5, 3.5]]}'
{"original_type":"list","optimized_type":"list","pattern_applied":"duplicates_removed — list preserved","original_size":88,"optimized_size":88,"saved":"0 bytes","optimized":["hello","world","python"]}
curl --location --request POST 'https://zylalabs.com/api/12866/python+data+optimizer+api/25671/optimize+structural' --header 'Authorization: Bearer YOUR_API_KEY'
--data-raw '{"data": ["hello", "world", "hello", "python"]}'
| हेडर | विवरण |
|---|---|
Authorization
|
[आवश्यक] होना चाहिए Bearer access_key. जब आप सब्सक्राइब हों तो ऊपर "Your API Access Key" देखें। |
कोई लंबी अवधि की प्रतिबद्धता नहीं। कभी भी अपग्रेड, डाउनग्रेड या कैंसल करें। फ्री ट्रायल में 50 रिक्वेस्ट तक शामिल हैं।
O endpoint Optimize Data एक JSON ऑब्जेक्ट लौटाता है जिसमें डेटा की संरचना को ऑप्टिमाइज़ किया गया है एक रिपोर्ट जो मूल और ऑप्टिमाइज़ किए गए आकारों और पता लगाया गया डेटा प्रकार का विवरण देती है
प्रतिक्रिया में मुख्य क्षेत्र "optimised" (अनुकूलित डेटा संरचना) "savings" (एक वस्तु जिसमें "original_type" "optimized_type" "original_size" "optimized_size" और "saved" शामिल हैं) और "type_detected" (पहचानी गई डेटा प्रकार) हैं
उत्तर डेटा को JSON प्रारूप में व्यवस्थित किया गया है जिसमें एक "status" फ़ील्ड है जो सफलता या विफलता इंगीत करता है इसके बाद एक "result" ऑब्जेक्ट है जिसमें अनुकूलित डेटा और बचत रिपोर्ट है
ओ एंडपॉइंट ऑप्टिमाइज़ डाटा संरचित डेटा के बारे में जानकारी प्रदान करता है ऑप्टिमाइज्ड और मूल आकारों के बारे में बचाई गई मेमोरी की मात्रा और पहचाने गए डेटा के प्रकार
उपयोगकर्ता अपने डेटा अनुरोधों को विभिन्न पायथन डेटा संरचनाओं को भेजकर कस्टमाइज़ कर सकते हैं कोड स्निप्पेट्स या डेटाबेस कनेक्शन स्ट्रिंग्स को JSON प्रारूप में संलग्न करके ताकि उनकी विशिष्ट आवश्यकताओं के आधार पर अनुकूलन किया जा सके
उत्तर में "original_size" डेटा के आकार को इंगित करता है जो ऑप्टिमाइजेशन से पहले है "optimized_size" ऑप्टिमाइजेशन के बाद का आकार दिखाता है और "saved" ऑप्टिमाइजेशन की प्रक्रिया के माध्यम से प्राप्त की गई मेमोरी की कटौती को मापता है
रुचिकर उपयोग के मामलों में पायथन एप्लिकेशनों में मेमोरी उपयोग को कम करना, भंडारण लागत को कम करने के लिए डेटाबेस कॉलम प्रकारों का अनुकूलन करना, मेमोरी लीक की पहचान करना और मशीन लर्निंग कार्यों के लिए स्पार्स मैट्रिक्स को संकुचित करना शामिल है
डेटा की सटीकता को बनाए रखा जाता है जब असमर्थित डेटा प्रकारों की पहचान और बुद्धिमानी से प्रतिस्थापन किया जाता है जबकि यह सुनिश्चित करते हुए कि अनुकूलित प्रकारों में मूल डेटा का सही प्रतिनिधित्व किया जाए ताकि अनुकूलन प्रक्रिया के दौरान उसकी अखंडता को बनाए रखा जा सके
एपीआई विभिन्न पायथन डेटा संरचनाओं को अनुकूलित कर सकता है जिसमें सूचियाँ, ऐरे, शब्दकोश और विरल मैट्रिसेस शामिल हैं यह कोड स्निपेट्स और डेटाबेस कनेक्शन स्ट्रिंग्स का भी समर्थन करता है जिससे अनुकूलन परिदृश्यों की एक विस्तृत श्रृंखला संभव है
एपीआई गहराई से घुंघराले सूचियों को सपाट एरे में समतल कर सकता है जो जटिलता और मेमोरी उपयोग को कम करता है यह फीचर विशेष रूप से मशीन लर्निंग कार्यों में सामान्य रूप से पाए जाने वाले डेटा संरचनाओं का ऑप्टिमाइज़ करने के लिए उपयोगी है
"type_detected" क्षेत्र उस मूल डेटा प्रकार को दर्शाता है जिसे एपीआई ने अनुकूलन से पहले पहचाना था यह उपयोगकर्ताओं को यह समझने में मदद करता है कि किस प्रकार के डेटा को संसाधित किया गया था और यह सुनिश्चित करता है कि वे अनुकूलन परिणामों की पुष्टि कर सकें
हां, API विभिन्न डेटाबेस सिस्टमों के लिए अनुकूलन का समर्थन करता है, जिसमें PostgreSQL, MySQL, SQLite, MongoDB और SQL Server शामिल हैं। यह डेटा भंडारण की दक्षता बढ़ाने के लिए प्रत्येक प्रणाली के लिए अनुकूलित सिफारिशें प्रदान करता है
यदि इनपुट डेटा पहले से ही अनुकूलित है तो एपीआई अभी भी एक बचत रिपोर्ट लौटाएगा जो संकेत देता है कि आगे का अनुकूलन आवश्यक नहीं है यह उपयोगकर्ताओं को उनके मौजूदा डेटा संरचनाओं की दक्षता की पुष्टि करने में मदद करता है
एपीआई बुद्धिमानी से अप्रभावी डेटा प्रकारों की पहचान करता है और उन्हें बदलता है जबकि यह सुनिश्चित करता है कि अनुकूलित प्रकार मूल डेटा का सही प्रतिनिधित्व करते हैं यह प्रक्रिया डेटा की अखंडता बनाए रखती है और जानकारी के नुकसान को रोकती है
सूचियों को सेट में परिवर्तित करना डुप्लिकेट मानों को समाप्त करता है जिससे मेमोरी की बचत होती है जबकि ट्यूपल का उपयोग अपरिवर्तनीयता प्रदान करता है जो प्रत्येक संरचना के लिए लगभग 40 बाइट्स मेमोरी उपयोग को कम कर सकता है दोनों परिवर्तनों से डेटा की दक्षता बढ़ती है
बचत रिपोर्ट मूल आकार अनुकूलित आकार और कुल बचाए गए बाइट्स का विवरण देती है उपयोगकर्ता इस जानकारी का उपयोग अनुकूलन की प्रभावशीलता का आकलन करने और डेटा प्रबंधन के बारे में सूचित निर्णय लेने के लिए कर सकते हैं
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
1,473ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
16ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
625ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
8,561ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
1,007ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
3,574ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
8,434ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
0ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
2,507ms
सर्विस लेवल:
100%
रिस्पॉन्स टाइम:
6,392ms